一、操作系统
1.ping判断:windows的TTL值一般为128,Linux则为64.
TTL大于100的一般为windows,几十的一般为linux。
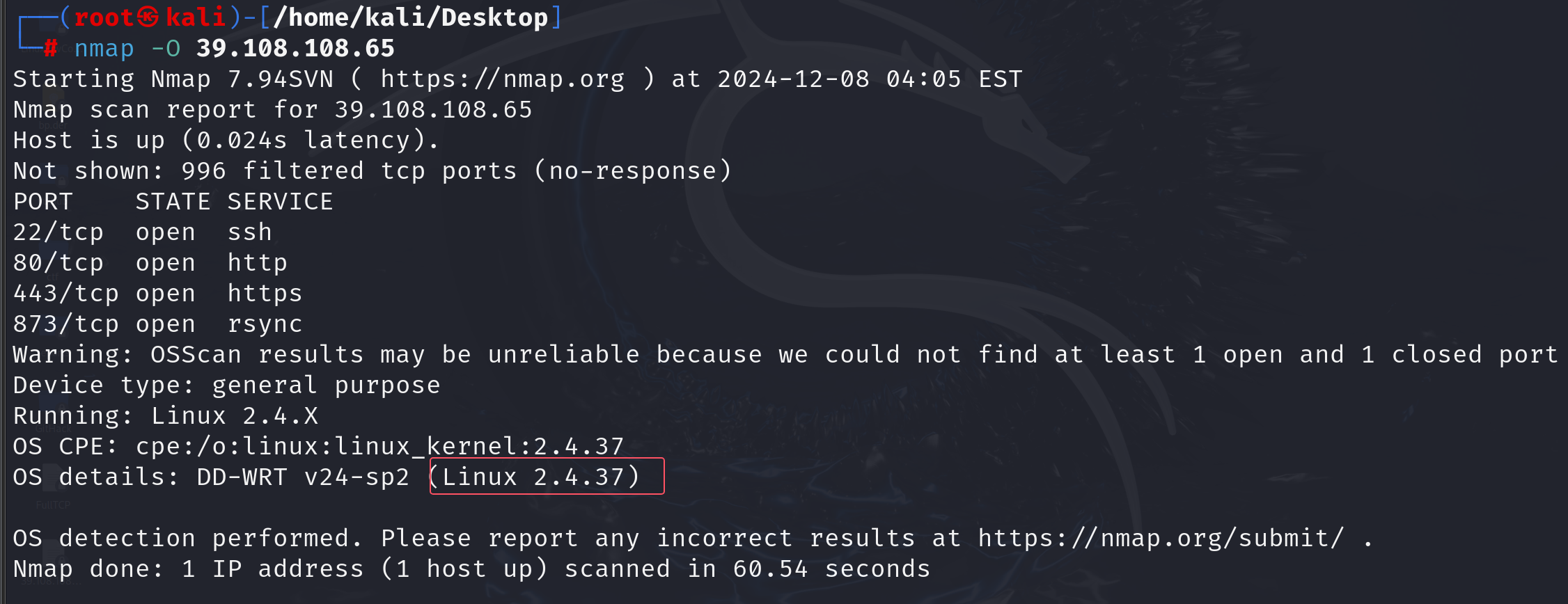
2.nmap -O参数
3.windows 大小写不敏感,linux 则区分大小写
二、网站服务、容器类型
1.F12查看响应头 Server 字段
2.whatweb :https://www.kali.org/tools/whatweb/
3.wappalyzer插件
apache ,nginx,tomcat,llS
通过容器类型、版本可考虑对应容器存在的漏洞(解析漏洞)
三、脚本类型
1.php
2.jsp
3.asp/aspx
4.python
知道是什么语言才可以针对性的进行文件扫描、文件上传
四、数据库类型
在进行SQL注入之前,首先应该判断数据库的类型,不同的数据库在处理一些函数的时候会有一些微妙的差别,只有判断出是哪种数据库类型,这样才能根据数据库的类型选择合适的函数,更容易实现SQL注入。
1.常见数据库类型
1.Oracle
2.MySQL
3.SQL Server
4.Postgresql
5.Mongodb
6.Access
2.前端与数据库类型
asp:SQL Server,Access
.net:SQL Server
php:MySQL,PostgreSQL
java: Oracle,MySQL
3.常见数据库端口
Oracle:默认端口 1521
MySQL:默认端口 3306
SQL Server:默认端囗 1433
Postgresql:默认端口 5432
Mongodb:默认端口 27017
Access:文件型数据库,不需要端口
根据数据库特有函数来判断
根据特殊符号进行判断
根据数据库对字符串的处理方式判断
根据数据库特有的数据表来判断
根据盲注特别函数
五、CMS识别
CMS:内容管理系统,用于网站内容文章管理
常见CMS:WordPress、Joomla、Drupal、dedecms(织梦)、Discuz、phpcms等
识别工具:wpscan(kali自带)
六、敏感文件、目录
1.常见敏感文件或目录
robots.txt
crossdomain.xm
sitemap.xml
后台目录
网站安装目录
网站上传目录
mysql管理页面
phpinfo
网站文本编辑器
测试文件
网站备份文件(.rar、.zip、.7z、.tar、.gz、.bak)
DS_Store文件
vim编辑器备份文件(.swp)
WEB-INF/web.xml文件
敏感文件、敏感目录挖掘一般都是靠工具、脚本来找,比如御剑、dirsearch,当然大佬手工也能找得
到。
2.robots.txt
robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被搜索引擎访问的部分,或者指定搜索引擎只收录指定的内容。当一个搜索引擎(又称搜索机器人或蜘蛛程序)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取。
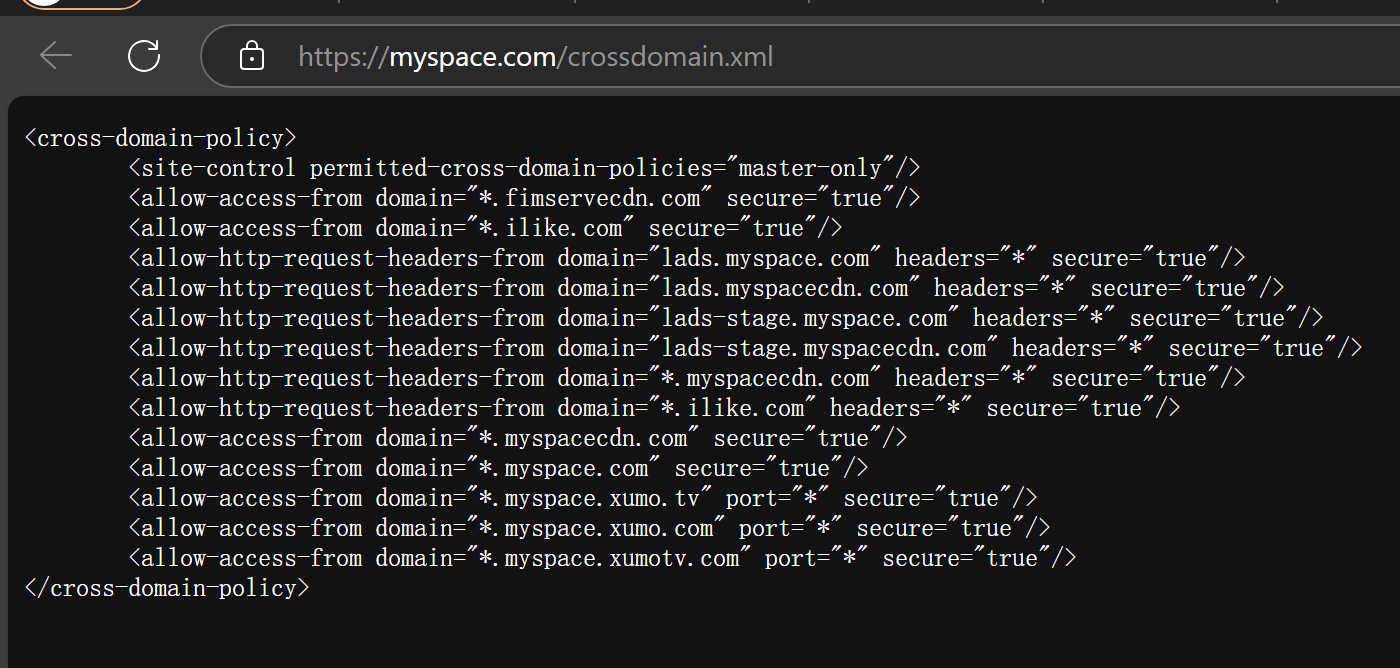
3.crossdomain.xml
跨域,顾名思义就是需要的资源不在自己的域服务器上,需要访问其他域服务器。跨域策略文件是一个xml文档文件,主要是为web客户端(如Adobe Flash Player等)设置跨域处理数据的权限。重点查看a11ow-access-from字段获取网站目录信息
GoogleHacking语法:
inurl:crossdomain filetype:xml intext:allow-access-from
例子:
myspace.com/crossdomain.xml
4.sitemap.xml
5.源代码泄露
6.Github泄露
7..git泄露
要有==index文件==才可以利用
GoogleHacking语法:
".git" intitle:"index of"
工具:Githack(kali有)
GitHack是一个.git泄露利用脚本,通过泄露的.git 文件夹下的文件,重建还原工程源代码。
8.svn泄露
和.git泄露一样
工具:svnExploit
9.WEB-INF/web.xml泄露
WEB-INF是Java的Web应用的安全目录,如果想在页面中直接访问其中的文件,必须通过web.xml文件对要访问的文件进行相应映射才能访问。
通过找到 web.xm 文件,推断 class 文件的路径,最后直接下载 class 文件,再通过反编译 class 文件,得到网站源码。
10.敏感目录收集
11.网站备份文件
12.目录扫描探测
目录扫描可以让我们发现这个网站存在多少个目录,多少个页面,探索出网站的整结构。通过目录扫描我们还能扫描敏感文件,后台文件,数据库文件,和信息泄漏文件等等
目录扫描有两种方式:
1.使用目录字典进行暴力猜解可能存在的目录或文件,通过返回的响应状态码判断是否存在,返回200或者403
2.使用爬虫爬取页面上的所有链接,对每个链接进行再次爬行,收集这个域名下的所有链接,然后总结出存在页面的信息
目录扫描工具:dirsearch(kali)
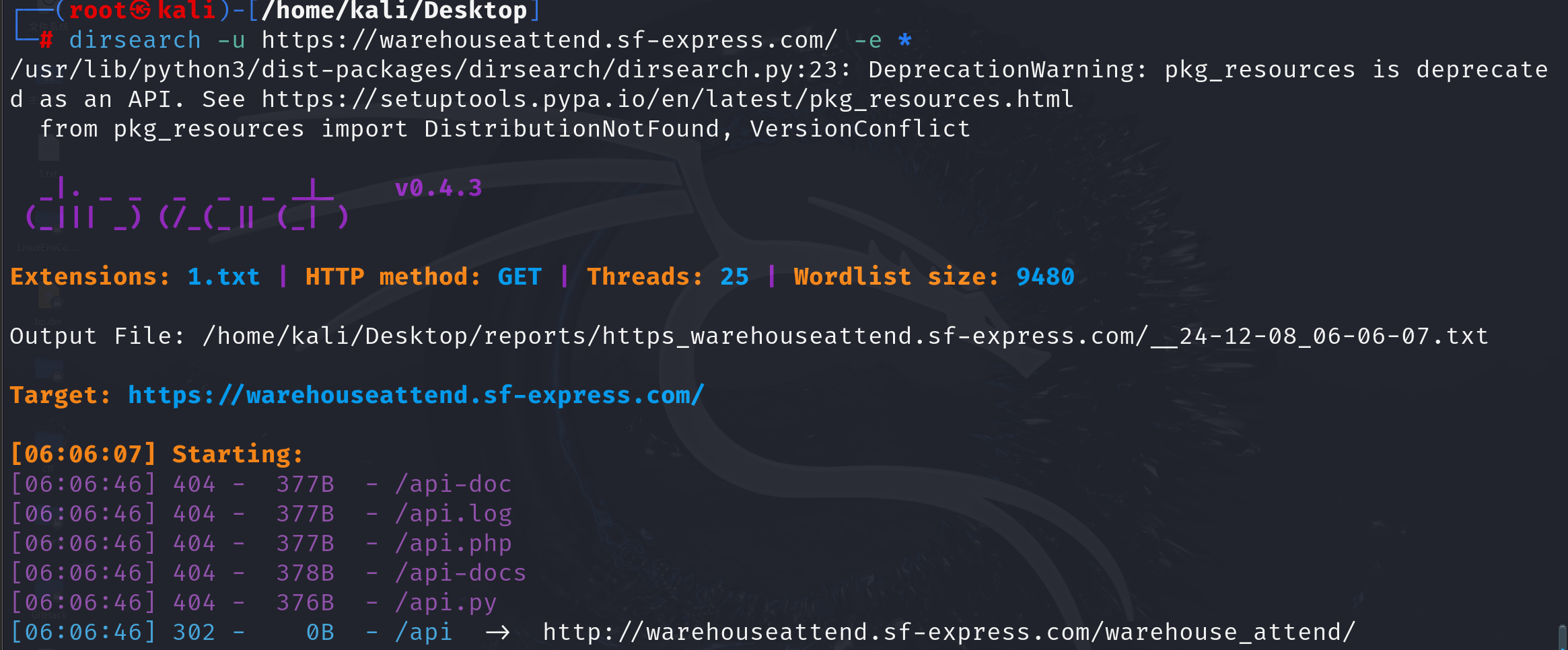
-e * 扫描所以目录
关注302 301 403状态
二次扫描
7.网站WAF识别
WAF功能
1.防止常见的各类网络攻击,如:SQL注入、XSS跨站、CSRF、网页后门等
2.防止各类自动化攻击,如:暴力破解、撞库、批量注册、自动发贴等;
3.阻止其它常见威胁,如:爬虫、0 DAY攻击、代码分析、嗅探、数据篡改、越权访问、敏感信息泄漏
应用层DDOS、远程恶意包含、盗链、越权、扫描等。
WAF识别工具:
wafw00f(kali)
nmap
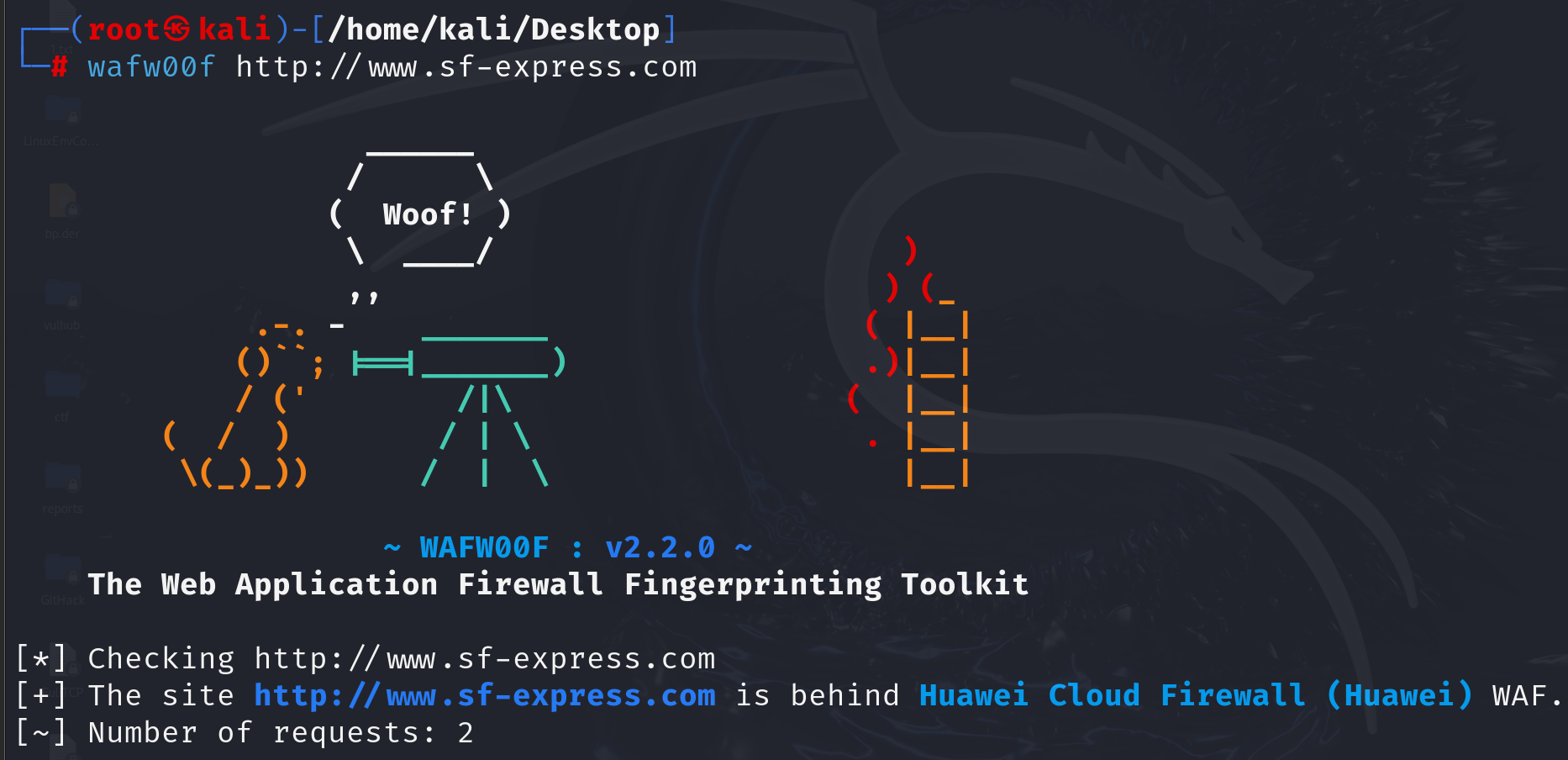
可以知道顺丰的waf是华为云,然后搜索绕过方法
或者看报错页面识别WAF|